Canbrowser Enterprise Data Sync Case Study
Canbrowser is a specialized enterprise web application responsible for synchronizing and maintaining product information originating from two external systems—Jeeves (ERP) and Kvaser (resource management). The platform processes massive datasets, ensuring that product prices, web/list price variations, resource files, versions, release notes, descriptions, and inter-product relations are consistently updated.
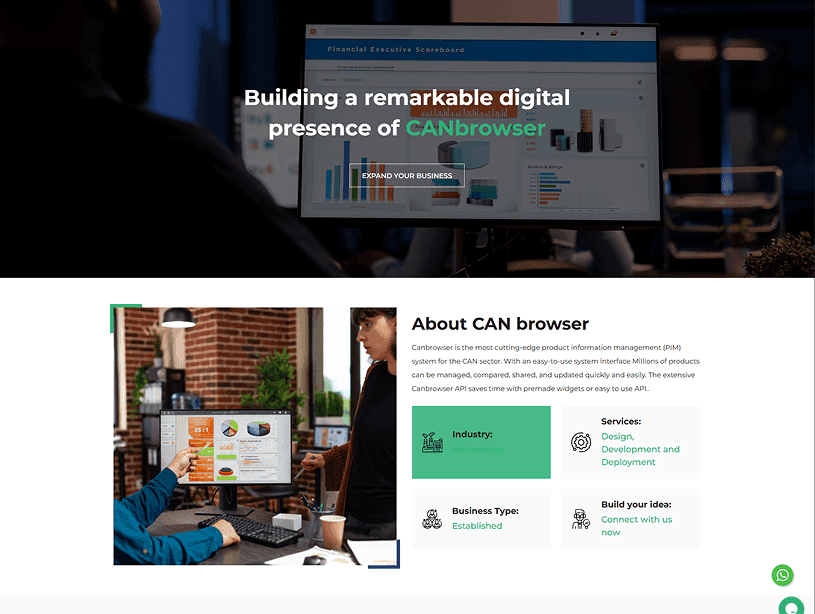
Process maturity
CMMI Level 5
Information security
ISO 27001
Industry experience
25+ years
Global clients served
600+
Project Scope & Challenges
The client faced several technical and operational constraints:
Representing a vast and highly customizable product range, from simple chairs to intricate cabinetry.
Enabling clients to customize materials, finishes, upholstery, and dimensions through an intuitive digital experience.
Showcasing craftsmanship through high-end imagery, elegant UI, and luxury-driven visual identity.
Creating a portfolio hub for completed bespoke projects across multiple industries.
Supporting trade-client workflows, including privileged access, pricing tiers, and project-specific inquiries
Integrating a CRM system to streamline custom orders, product status updates, and internal workflows.
Ensuring seamless performance across mobile and desktop for a global clientele
Mapelcode’s Solution
Mapelcode re-engineered the backend synchronization framework to deliver stability, performance, and accuracy across both major modules:
Product Price Sync (via Jeeves APIs)
Implemented robust API integration to fetch and update both web price and list priceOptimized mapping and transformation logic for large-scale product datasets Ensured pricing accuracy with improved validation and cross-check mechanisms
Resource Sync (via Kvaser APIs)
Streamlined syncing of products, resources, versions, files, and multi-language descriptionsImproved handling of file data, version histories, relations, and detailed metadataEnsured smooth compatibility across multiple resource types
Backend Enhancements Across Modules
Added batching to process large data volumes efficientlyImplemented multi-level retry logic to prevent failures in long-running sync jobsStrengthened exception handling and audit logs for 3-4 hour operationsEnhanced data mapping rules to reduce mismatches significantlyDelivered Admin UI enhancements for better visibility and manual sync triggers
Tools & Technologies We Leverage
Backend
 Java
Java Spring Boot
Spring Boot Rest APIs
Rest APIsIntegrations
 Jeeves Product Price APIs
Jeeves Product Price APIs Kvaser Resource APIs
Kvaser Resource APIsDatabase
 MySQL
MySQLData Processing
 JSON/XML parsin
JSON/XML parsin
Results & Achievements
Mapelcode’s engineering improvements delivered measurable business and operational impact:
Highly stable 3-4 hour sync processes with reduced failure rates
Accurate and consistent product pricing across systems
Significant reduction in data mismatches reported by end users
Efficient processing of large datasets with improved performance
Reliable syncing of multi-language descriptions and resource histories
Admin teams gained greater control through enhanced UI and monitoring
Overall improvement in system reliability, maintainability, and scalability
Highly stable 3-4 hour sync processes with reduced failure rates
Accurate and consistent product pricing across systems
Significant reduction in data mismatches reported by end users
Efficient processing of large datasets with improved performance
Reliable syncing of multi-language descriptions and resource histories
Admin teams gained greater control through enhanced UI and monitoring
Overall improvement in system reliability, maintainability, and scalability
Unlock High-Performance Enterprise Integrations That Scale with Your Business
Mapelcode helps enterprises modernize and optimize their backend ecosystem with scalable, API-driven data sync solutions. Whether you’re integrating ERPs, resource systems, or multi-platform data pipelines, our engineering teams ensure reliability, accuracy, and long-term performance.
From the Mapelcode Engineering Lab
The intelligence layer behind how Mapelcode teams plan, engineer, test, release, and govern enterprise software.
Keep exploring.
Let's build something like this.
Share your challenge and we'll put together the right team, stack, and approach — just like we did for these clients.